회귀 모형의 예측 결과는 수치로 나타나며, 실제 값과 예측 값의 차이가 작을수록(=편향이 작을수록, 오차가 작을수록) 성능이 좋다고 할 수 있다. 그렇기 때문에 일반적으로 회귀 모형을 평가할 때는 오차를 다양한 방식으로 평균하여 계산한 지표를 사용하며, 결정계수도 중요 지표로 사용한다.
1. 평가 지표
예측 오차를 이용해 회귀 모형의 성능을 평가하는 지표이다. 대표적인 것이 MAE와 MSE인데 MSE는 손실함수로, MAE는 회귀지표로 보통 사용된다.
(1) MAE (평균절대오차)
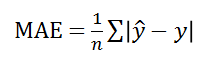
오차 절대값의 평균으로 직관적이고 예측변수와 단위가 같다는 장점이 있다. 다만 에러의 크기를 그대로 반영해서 이게 under estimated인지 over estimated인지 파악하기가 어렵다.
(2) MAPE (평균절대비율 오차)
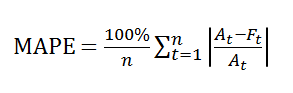
(실제값-예측값)/실제값의 절대값의 합을 비율로 나타낸 것이다. 오차의 비율로 모델을 비교할 수 있기 때문에 오차 평균의 크기가 크게 차이나는 모델 간의 비교도 가능하다. 단, 비율이기 때문에 직관적으로 오차를 확인하기는 어렵다.
실제 값이 0인 경우 구할 수 없고 실제 값이 0에 거까워지면 값이 극단적으로 커진다는 단점이 있다.
(3) MSE (평균 제곱 오차)
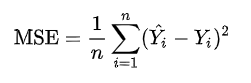
잔차를 제곱하여 평균한 값으로 계산이 쉽고 분석이 용이해 추정 정확도 척도로 가장 많이 사용된다. MSE는 회귀에서 자주 사용되는 손실함수이며, 손실(잔차)는 작을수록 좋기 때문에 MSE도 수치가 작을수록 회귀 모델의 정확도가 높다고 할 수 있다. 다만 과도하게 줄이면 오버피팅이 발생할 수 있다.
다만, 예측 변수와 단위가 다르며 잔차를 제곱하기 때문에 실제 오류보다 더 커지는 경향이 있고 아웃라이어에도 민감하다.
(4) RMSE (평균 제곱근 오차)
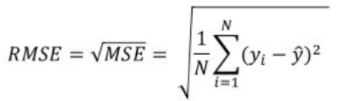
RMSE는 MSE에 루트를 씌운 값으로 예측 변수와 단위가 같다. MSE가 오류의 제곱을 구하기 때문에 실제 오류 평균보다 커지는 특성이 있어 이를 보완하기 위해 루트를 씌우는 것이다.
(5) RMSLE
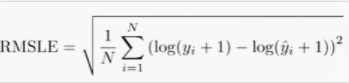
RMSLE는 RMSE에 로그를 취해준 값으로 아웃라이어의 영향을 많이 받지 않고 상대적 에러를 구해준다는 장점이 있다. RMSE는 상대적 크기가 동일해도 절대적 크기가 변하면 값이 변하지만, RMSLE는 상대적 크기가 동일하다면 절대적 크기가 변해도 값이 변하지 않는다.
또 over estimation보다 under estimation에 더 큰 패널티를 부여한다는 특징도 있다.
2. 결정계수(R²)
결정계수는 선형 회귀 모형이 실제 데이터를 얼마나 잘 설명하는지 나타내는 지표로 1에 가까울수록 모형의 설명력이 높다.
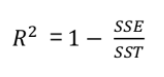
| SST (Total Sum of Squares) | -전체 제곱합 -실제 관측치와 y값들의 평균의 차이를 제곱하여 합한 값 -y가 갖는 전체 변동 |
| SSR (Regression Sum of Squares) | -회귀 제곱합 -예측치와 y값들의 평균의 차이를 제곱하여 합한 값 -y가 갖는 전체 변동성 중 회귀 모형으로 설명할 수 있는 변동 |
| SSE (Error Sum of Sqaures) | -오차제곱합 -실제 관측치와 예측의 차이를 제곱하여 합한 값 -y가 갖는 전체 변동성 중 회귀 모형으로 설명할 수 없는 변동 |
이때 SSE=0이라는 것은 오차가 아예 없다는 의미로 R²는 1이 된다. 만약 R²가 0이라고 해도 X와 Y가 아무런 상관관계가 없다고 할 수는 없다. 그저 선형 상관관계가 없다는 의미이며 비선형 관계를 가질 수도 있다.
변수의 수가 증가하면 자연스럽게 SSR이 증가하고 R²도 증가하기 때문에 R²가 크다고 모델의 성능이 무조건 좋다고 할 수는 없다. 회귀계수의 부호와 크기, 통계적 유의성, 추정의 정확성, 모형에 포함되지 않은 외부요인 등을 종합적으로 고려할 필요가 있다.
즉, R²는 중요한 기준이 될 수 있지만 절대적인 기준은 아니라는 점!
'파이썬 > 모델 성능평가' 카테고리의 다른 글
| ROC 곡선(ROC curve)과 AUC란? 직접 그려보기 (0) | 2021.07.13 |
|---|---|
| 그리드 서치로 최적화 하이퍼파라미터 찾기 (GridSearchCV) (0) | 2021.06.29 |
| validation set이란? test set과의 차이점과 사용 방법 (0) | 2021.06.27 |
| 쉽게 알아보는 K겹 교차검증(K-fold cross validation) 개념과 코드 (0) | 2021.06.06 |
| F1 score와 accuracy, 분류기의 성능 평가 지표 (0) | 2021.06.06 |



