ROC곡선은 이진분류기의 성능을 측정하는 도구이다.
ROC곡선의 생김새는 언뜻보면 recall-precision 곡선과 비슷해보이지만 FPR에 대한 TPR의 곡선이다.
(X축이 FPR, Y축이 TPR)
FPR(False Positive Rate): 거짓 양성 비율 (실제로는 음성인데 양성으로 잘못 분류)
TPR(True Positive Rate): 진짜 양성 비율 (실제로도 양성이고 양성으로 잘 분류)
일단 ROC 커브에 대해 알아보기 전에 그 기본이 되는 오차행렬과 재현율, 정밀도에 대해서 먼저 짚고 넘어가자.

위 그림은 오차행렬이다. 오차행렬에서 TN, TP는 실제 음성/실제 양성 클래스를 각각 음성, 양성으로 정확하게 분류한 것이다. FP는 실제로는 음성인데 양성으로 잘못 분류된 것, FN은 실제로는 양성인데 음성으로 잘못 분류된 것이다.
정확도: 정확히 예측한 수/전체 샘플 수
정밀도: 진짜 양성 샘플 수/양성으로 예측된 샘플 수
재현율: 양성으로 분류된 샘플 수/전체 양성 샘플 수
보통 정밀도는 FP(거짓 양성)의 수를 줄이는 것이 목표일 때 성능 지표로 사용하고,
재현율은 FN(거짓 음성)을 피하는 것이 목표, 즉 거짓 양성이 일부 포함되더라도 모든 양성 샘플을 식별하는 것이 중요할 때 성능 지표로 사용한다.
TN이 하나도 없고 모두 양성 클래스라고 예측하면 FN이 없기 때문에 재현율이 완벽해진다. 하지만 모든 클래스를 양성으로 예측하면 거짓 양성이 많아질 수밖에 없기 때문에 정밀도는 매우 낮아진다. 그렇기 때문에 재현율의 최적화와 정밀도 최적화는 상충된다.
추가로 사이킷런 metrics의 classification_report를 사용하면 precision, recall, f1-score을 한번에 확인할 수 있다.
from sklearn.datasets import load_breast_cancer
from sklearn.metrics import precision_recall_curve, roc_curve, classification_report
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
data = load_breast_cancer()
X_train, X_test, y_train, y_test = train_test_split(data.data, data.target, test_size=0.4, random_state=42)
X_test, X_val, y_test, y_val = train_test_split(X_test, y_test, test_size=0.5, random_state=42)
rand_clf = RandomForestClassifier(n_estimators=200, random_state=42)
rand_clf.fit(X_train, y_train)
y_pred_val = rand_clf.predict(X_val)
print(classification_report(y_val, y_pred_val))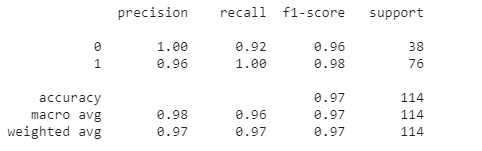
precision: positive라고 예측한 것 중에 얼마나 잘 맞았는지
recall: 실제 positive인 것을 얼마나 잘 예측했는지
F1-score: 조화평균
precision을 높이려면 FP를 줄여야 하고 recall을 높이려면 FN을 줄여야 해서 어느정도 트레이드 오프는 발생한다.
이제 ROC 커브를 직접 그려보자.
ROC 곡선의 X축은 FPR(허위 양성 비율), Y축은 TPR(참 양성 비율=재현율)이며 곡선이 원점에서 멀면 멀수록 성능이 좋음을 의미한다.
from sklearn.metrics import roc_curve
fpr, tpr, thresholds = roc_curve(y_val, rand_clf.predict_proba(X_val)[:,1])
plt.plot([0,1], [0,1], "k--", "r+")
plt.plot(fpr, tpr, label='RandomForest')
plt.xlabel('FPR')
plt.ylabel('TPR')
plt.title('RandomForest ROC curve')
plt.show()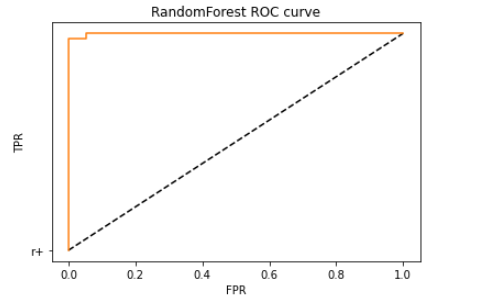
AUC는 Area Under the ROC Curve의 줄임말로 ROC커브 와 직선 사이의 면적을 의미한다. AUC 값의 범위는 0~1이며 값이 클수록 예측의 정확도가 높다고 할 수 있다. AUC 역시 사이킷런에서 제공하는 메서드로 계산할 수 있다.
from sklearn.metrics import roc_auc_score
rand_score = roc_auc_score(y_val, rand_clf.predict_proba(X_val)[:,1])
rand_score
>>>0.9986149584487535
위 ROC 커브의 AUC 값을 계산한 코드이다.
참고로 recall-precision 커브 코드는 아래와 같다.
import matplotlib.pyplot as plt
%matplotlib inline
plt.plot(precision, recall, label='rand')
plt.xlabel('recall')
plt.ylabel('precision')
plt.legend(loc='best')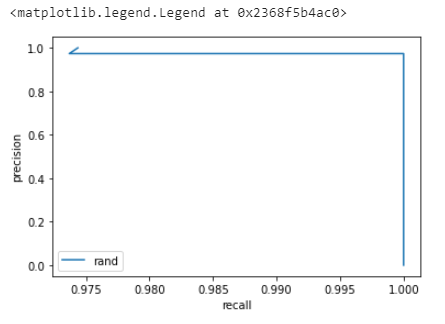
추가로 사이킷런 메서드로 average-precision-score를 구할 수도 있다.
from sklearn.metrics import average_precision_score
avg_score = average_precision_score(y_val, rand_clf.predict_proba(X_val)[:,1])
avg_score
>>>0.9993208545840125'파이썬 > 모델 성능평가' 카테고리의 다른 글
| 회귀 평가지표 - MAE, MSE, R² (0) | 2021.09.30 |
|---|---|
| 그리드 서치로 최적화 하이퍼파라미터 찾기 (GridSearchCV) (0) | 2021.06.29 |
| validation set이란? test set과의 차이점과 사용 방법 (0) | 2021.06.27 |
| 쉽게 알아보는 K겹 교차검증(K-fold cross validation) 개념과 코드 (0) | 2021.06.06 |
| F1 score와 accuracy, 분류기의 성능 평가 지표 (0) | 2021.06.06 |



