딥러닝은 머신러닝의 한 방법으로 대용량 비정형 데이터 분석을 위한 인공신경망 기반 머신러닝 알고리즘이다. 연속된 층(layer)에서 점진적으로 의미 있는 표현을 배우는데 강점이 있다. 딥러닝의 딥(deep)이라는 단어 때문에 다소 혼란이 올 수 있지만 이 '딥'은 모델을 만드는데 얼마나 많은 층을 사용했는지를 의미한다. 최근의 딥러닝 모델은 표현 학습을 위해 수 십, 수 백개의 연속된 층을 사용한다.
현재 딥러닝은 이미지 인식, 음성인식, 자연어처리 등 인공지능 분야의 핵심 기술로 자리잡았다.
1. 인공신경망(RNN)
인공신경망은 사람 두뇌의 신경세포인 뉴런이 전기신호를 전달하는 모습을 모방한 머신러닝 모델이다. 입력값을 받아서 출력값을 만들기 위해 활성화 함수를 사용한다.
뉴런은 간단한 계산 능력을 가진 처리 단위로 인공신경망 모델에서 뉴런은 층으로 구성되고 층은 여러 개의 노드로 구성된다. 1개의 노드는 1개 이상의 노드와 연결되어 있고, 입력 데이터를 기초로 가중치를 구해 의사결정을 한다. 블랙박스 형태로 데이터를 입력하면 자동으로 복잡한 수학식 모델링이 되는 기법이다.
딥러닝은 이러한 인공신경망을 이용한 알고리즘으로 데이터를 학습하며 예측 정확성 여부를 스스로 한다.
(1)활성화 함수
인공신경망은 노드에 입력된 값을 비선형 함수에 통과시켜 다음 노드로 전달하는데, 이 비선형 함수를 활성화 함수라고 한다. 활성 함수는 입력 값을 적절히 변환하며 변환 출력된 값을 다음 노드에서 활성화할 지 결정한다.
선형함수를 사용하면 결과 영역을 나누는 선이 단순한 직선이기 때문에 층을 깊게 쌓는 의미가 없어 비선형 함수인 계단 함수를 사용해 결과 영역을 나누는 선을 곡선으로 표현한다.
①시그모이드 함수
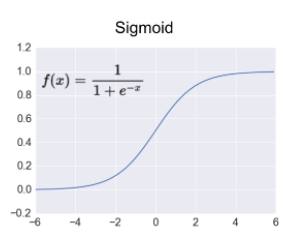
시그모이드 함수는 로지스틱 회귀 모델에서 한 번 본 함수이다. logg-odds값을 확률값으로 리턴해주는 함수였다. 0~1 사이의 값을 출력하는 함수인데, 은닉층을 거칠 떄미다 출력 값이 0으로 수렴하는 기울기 소실의 문제가 있어 최근에는 ReLU함수를 더 많이 사용한다.
②ReLu함수

입력값이 음수이면 0을, 양수이면 입력값을 그대로 출력하는 함수이다. 앞선 시그모이드 함수의 기울기 소실 문제를 해결할 수 있고 연산이 빠르다는 장점이 있지만 0보다 작은 값에 대해서는 뉴런이 작동하지 않을 수 있다.
이런 문제를 개선한 Leaky ReLU함수는 입력값이 음수일 떄 입력값의 1/10만 출력하여 렐루 함수의 단점을 보완했다.
③Tanh함수
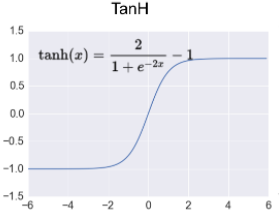
시그모이드 함수의 확장된 형태로 -1 ~ 1사이의 값을 출력하고 시그모이드 함수보다 학습속도가 더 빠르다.
(2) 신경망의 계층구조
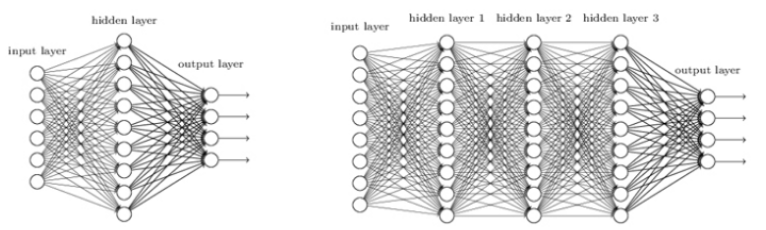
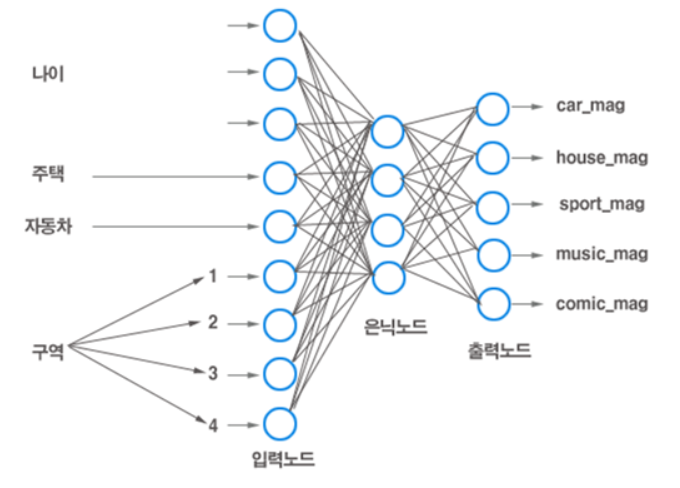
인공신경망은 입력층, 은닉층, 출력층으로 구성되며 은닉층은 필요에 따라 하나 이상의 층으로 구성될 수 있다.
입력층: 데이터를 입력 받는 층
은닉층: 입력층으로부터 전달받은 값을 이용해 가중합과 편향을 계산하고 활성함수에 적용해 결과 산출
출력층: 활성함수의 결과를 출력, 출력 범주의 수와 같음
(3)역전파 알고리즘
역전파는 인공신경망에서 아주 중요한 개념이다. 인공신경망을 학습시키기 위한 일반적인 알고리즘으로 출력값으로 결정된 결과값의 오차를 역으로 입력층으로 전파하면서 오차가 최소가 되도록 가중한다. 입력층에서부터 가중치를 조절하는 순전파 알고리즘에 비해 훨씬 빠르고 성능이 좋으며 텐서플로에서도 역전파 기법을 기본으로 제공한다.
*역전파 알고리즘의 동작 방법
1. 주어진 가중치 값으로 출력값 계산(순전파)
2. 오차를 각 가중치로 미분한 값을 기존 가중치에서 뺌(경사하강법 이용)
3. 1~2를 반복해서 주어진 학습 횟수 혹은 허용 오차에 도달할 때까지 반복
(4)퍼셉트론
퍼셉트론은 다수의 훈련 데이터를 이용해 일종의 지도학습을 수행하는 알고리즘이다. 입력값을 받으면 가중치를 곱한 후 활성홤수를 통과해 활성함수의 임계치를 넘으면 출력을 1로 뱉어 다음 퍼셉트론으로 전달한다. 만약 임계치를 넘지 못하면 출력이 활성화되지 않는다.

중간층을 노드 또는 뉴런이라고 하며 출력층은 노드의 출력값이 또 다른 노드로 전달되는 층이다.
위와 같이 중간층이 하나의 노드로 구성되어서 중간층과 출력층의 구분이 없는 구조가 단순/단층 퍼셉트론이다. 단층 퍼셉트론은 AND, OR 연산은 가능하지만 XOR은 선형 분리가 불가능하다는 한계가 있다. XOR은 exclusive OR로 하나의 함수만으로는 분류가 불가능한 형태이다. 그렇기 떄문에 다항 커널이나 rbf커널을 이용해서 곡선적으로 분류한다.
다층 퍼셉트론은 입력층과 출력층 사이에 하나 이상의 은닉층을 추가해 비선형 데이터에 대한 학습을 가능하게 한 퍼셉트론 구조이다. 은닉층이 없는 단층 퍼셉트론과 달리 은닉층을 가지며, 역전파 알고리즘을 사용하고 활성함수로는 시그모이드 함수를 사용한다. 그렇기 때문에 오버피팅과 기울기 소실 문제가 발생한다. 기울기 소실 문제는 시그모이드 함수 대신 ReLU함수를 사용해서 해결할 수 있다.
단층 퍼셉트론을 여러 층 쌓은 비선형 분류기로 XOR를 포함한 다양한 비선형 분류 문제를 해결할 수 있다.
2. 주요 하이퍼파라미터
| learning rate | 학습 속도, 파라미터의 업데이트 정도를 조절 |
| epoch | 전체 데이터 학습 횟수, forward pass와 backward pass를 총 몇 번 진행할 것인지 |
| iteration | 반복 횟수 |
| mini-batch size | 한번의 배치에 사용되는 데이터 셋의 size |
learning rate는 학습 스텝의 크기, 학습 속도인데 너무 크게 설정하면 학습을 건너뛰게 된다. 반대로 너무 작게 설정하면 알고리즘이 최적값에 수렴할 때까지 너무 오랜 시간이 걸려 학습 성능이 떨어지거나 국소 최적치에 빠져 최적값을 찾기 전에 학습이 끝나버릴 수 있다.
*경사하강법(Gradient Descent)와 learning rate 조정의 중요성
배치는 모델의 가중치를 한번 업데이트 시킬 때 사용되는 샘플의 묶음이다. 만약 배치 사이즈가 20이라면 20개의 샘플 단위로 모델의 가중치를 한번씩 업데이트 하는 것이다. 예를 들어 전체 훈련set이 1000개고 배치 사이즈가 20이라면 총 50번의 iteration으로 훈련을 진행하는 셈이다.
만약 배치 사이즈가 너무 크면 한번에 처리해야 하는 양이 많아지기 때문에 학습 속도가 느려지고 메모리 부족 문제가 생길 수 있다.
에포크는 학습 횟수를 의미한다. 위의 예시에서 에포크가 10이라면 가중치를 50번 업데이트하는 것을 총 10번 반복하므로 토탈 500번 업데이트 되는 것이다.
'파이썬 > 머신러닝' 카테고리의 다른 글
| 나이브베이즈 가장 기초적인 지도학습 모델 (0) | 2021.09.28 |
|---|---|
| 로지스틱 회귀 개념 알아보기, 선형회귀와의 차이점 (0) | 2021.09.11 |
| k-평균 군집화 알고리즘 기본 개념과 예제 (0) | 2021.08.03 |
| 차원 축소 PCA(주성분 분석) 기본 개념 - 투영과 매니폴드 학습 (0) | 2021.08.01 |
| 차원의 저주 개념, 발생 원인과 해결 방법 (2) | 2021.08.01 |



